Stellen Sie sich vor: Ein kritischer Server fällt mitten in der Hauptgeschäftszeit aus. Kunden können nicht auf Ihre Dienste zugreifen, Mitarbeiter stehen vor schwarzen Bildschirmen. Hätte ein proaktives IT-Monitoring diesen Ausfall verhindern können? Absolut. IT Monitoring und Event Management funktionieren wie ein digitales Frühwarnsystem – sie erkennen Anomalien, bevor sie zu geschäftskritischen Problemen werden, und ermöglichen schnelle, oft automatisierte Reaktionen. Mit den richtigen Werkzeugen lassen sich Systemausfälle um bis zu 70% reduzieren.
Inhaltsverzeichnis
- Grundlagen des IT Monitoring & Event Management
- Vorteile eines effektiven Monitoring & Event Managements
- Komponenten eines umfassenden Monitoring-Systems
- Der Event Management Prozess im Detail
- Tools und Technologien für effektives Monitoring
- Best Practices für die Implementierung
- Fallstudien und Erfolgsbeispiele
- Zukunftstrends im IT Monitoring & Event Management
- Fazit und Handlungsempfehlungen
- Häufig gestellte Fragen
Grundlagen des IT Monitoring & Event Management
IT Monitoring und Event Management sind zwei eng miteinander verbundene Konzepte im IT Service Management. Das Monitoring umfasst die kontinuierliche Überwachung von IT-Systemen, während das Event Management sich auf die Erkennung und Behandlung von Ereignissen konzentriert.
Im ITIL-Framework ist ein Event “eine Statusänderung, die für das Management einer IT-Dienstleistung bedeutsam ist”. Events werden in drei Kategorien eingeteilt:
- Informative Events: Routinemäßige Aktivitäten ohne Handlungsbedarf
- Warnungen: Situationen, die Aufmerksamkeit erfordern könnten
- Ausnahmen/Incidents: Ereignisse, die sofortige Reaktion erfordern
Laut einer Studie des Bitkom können durch moderne IT-Monitoring-Systeme Ausfallzeiten um bis zu 65% reduziert werden. Ein effektives Event Management funktioniert dabei wie ein Frühwarnsystem – es identifiziert potenzielle Probleme frühzeitig und ermöglicht proaktives Handeln.
Vorteile eines effektiven Monitoring & Event Managements
Die Implementierung eines umfassenden IT Monitoring und Event Management Systems bietet Unternehmen zahlreiche Vorteile, die weit über die reine Fehlererkennung hinausgehen. Im Folgenden werden die wichtigsten Vorteile detailliert erläutert:
Erhöhte Systemverfügbarkeit und Zuverlässigkeit
Durch die kontinuierliche Überwachung kritischer Systeme und die proaktive Erkennung potenzieller Probleme können Unternehmen ihre Systemverfügbarkeit deutlich steigern. Laut einer Studie des Ponemon Institute kann ein ungeplanter Systemausfall Unternehmen durchschnittlich 9.000 Euro pro Minute kosten. Ein effektives Monitoring-System kann diese Ausfallzeiten um bis zu 70% reduzieren.
Frühzeitige Erkennung von Problemen
Moderne Monitoring-Systeme können Anomalien und potenzielle Probleme erkennen, lange bevor sie zu spürbaren Störungen führen. Dies ermöglicht IT-Teams, präventive Maßnahmen zu ergreifen und Probleme zu beheben, bevor Benutzer davon betroffen sind. Eine Untersuchung von IDC zeigt, dass Unternehmen mit proaktivem Monitoring 58% weniger kritische Incidents verzeichnen als solche mit reaktiven Ansätzen.
Reduzierung von Ausfallzeiten und deren Kosten
Durch schnellere Problemerkennung und -behebung werden Ausfallzeiten minimiert. Die durchschnittliche Zeit bis zur Wiederherstellung (Mean Time to Recovery, MTTR) kann durch automatisierte Event-Korrelation und vordefinierte Reaktionspläne um bis zu 50% reduziert werden. Dies führt zu erheblichen Kosteneinsparungen und einer höheren Kundenzufriedenheit.
Optimierung der IT-Ressourcen
Ein umfassendes Monitoring liefert wertvolle Einblicke in die Ressourcennutzung und Leistung von IT-Systemen. Diese Daten ermöglichen eine effizientere Ressourcenzuweisung und Kapazitätsplanung. Unternehmen können so Überkapazitäten vermeiden und gleichzeitig sicherstellen, dass genügend Ressourcen für Spitzenlasten zur Verfügung stehen.
Verbesserte Compliance und Sicherheit
Moderne Monitoring-Systeme unterstützen die Einhaltung von Compliance-Anforderungen durch automatisierte Berichterstattung und Audit-Trails. Gleichzeitig verbessern sie die Sicherheitslage durch die frühzeitige Erkennung von Sicherheitsvorfällen und ungewöhnlichen Aktivitäten. Laut dem Bundesamt für Sicherheit in der Informationstechnik (BSI) ist ein effektives Monitoring ein wesentlicher Bestandteil eines umfassenden IT-Sicherheitskonzepts.
ROI und Kosteneinsparungen
Obwohl die Implementierung eines umfassenden Monitoring-Systems mit Investitionen verbunden ist, zeigt eine Studie von Forrester Research, dass Unternehmen durchschnittlich einen ROI von 196% innerhalb von drei Jahren erzielen. Die Kosteneinsparungen resultieren aus reduzierter Ausfallzeit, effizienterer Ressourcennutzung und verbesserter Produktivität des IT-Personals.
Ein mittelständisches Fertigungsunternehmen konnte durch die Implementierung eines modernen Event Management Systems seine jährlichen IT-Betriebskosten um 22% senken, während gleichzeitig die Systemverfügbarkeit auf 99,95% stieg. Der Schlüssel zum Erfolg lag in der automatisierten Erkennung und Behebung von Routineproblemen, wodurch das IT-Personal sich auf strategischere Aufgaben konzentrieren konnte.
Komponenten eines umfassenden Monitoring-Systems
Ein effektives IT Monitoring und Event Management System besteht aus mehreren Komponenten, die zusammenarbeiten, um eine umfassende Überwachung der gesamten IT-Landschaft zu gewährleisten. Im Folgenden werden die wichtigsten Komponenten erläutert:
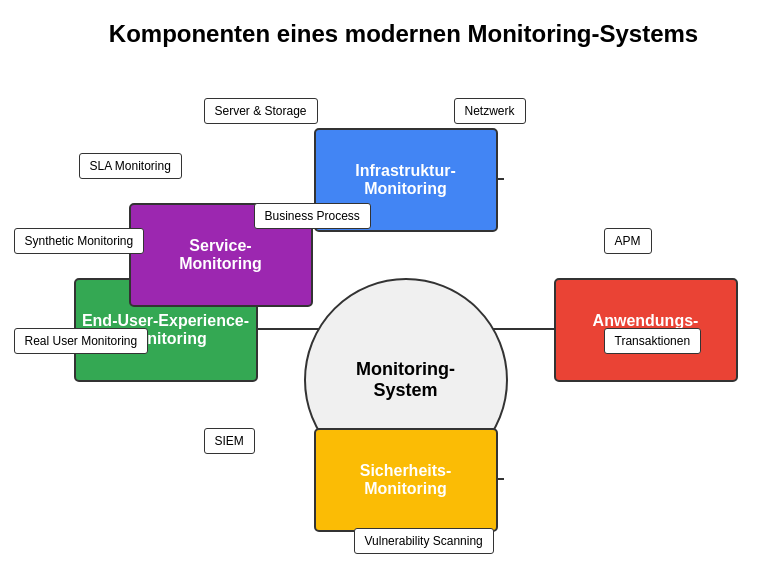
Infrastruktur-Monitoring
Das Infrastruktur-Monitoring bildet die Grundlage eines jeden Monitoring-Systems und umfasst die Überwachung von:
- Server-Monitoring: Überwachung von CPU-Auslastung, Arbeitsspeicher, Festplattenkapazität und Systemzustand
- Netzwerk-Monitoring: Überwachung von Netzwerkgeräten, Bandbreite, Latenz und Paketverlust
- Storage-Monitoring: Überwachung von Speicherkapazität, Performance und Verfügbarkeit
- Virtualisierungs-Monitoring: Überwachung von virtuellen Maschinen, Hypervisoren und Container-Umgebungen
Moderne Infrastruktur-Monitoring-Tools bieten detaillierte Einblicke in die Leistung und den Zustand der physischen und virtuellen Infrastruktur. Sie ermöglichen die frühzeitige Erkennung von Engpässen und potenziellen Ausfällen, bevor diese zu kritischen Problemen werden.
Anwendungs-Monitoring
Das Anwendungs-Monitoring konzentriert sich auf die Überwachung der Leistung und Verfügbarkeit von Anwendungen und umfasst:
- Application Performance Monitoring (APM): Überwachung von Antwortzeiten, Durchsatz und Fehlerraten
- Transaktions-Monitoring: Überwachung von Geschäftstransaktionen und deren Ausführungszeiten
- Code-Level-Monitoring: Tiefe Einblicke in die Anwendungsleistung auf Code-Ebene
- Datenbank-Monitoring: Überwachung von Datenbankleistung, Abfragen und Verbindungen
Anwendungs-Monitoring-Tools wie New Relic, Dynatrace oder AppDynamics bieten umfassende Einblicke in die Leistung von Anwendungen und helfen, Engpässe zu identifizieren und zu beheben. Sie ermöglichen es Entwicklern und Betriebsteams, Probleme schnell zu lokalisieren und zu beheben, was zu einer verbesserten Benutzererfahrung führt.
Service-Monitoring
Das Service-Monitoring geht über die technische Überwachung hinaus und konzentriert sich auf die Überwachung von IT-Services aus Geschäftsperspektive. Es umfasst:
- Service Level Agreement (SLA) Monitoring: Überwachung der Einhaltung von vereinbarten Servicelevels
- Business Process Monitoring: Überwachung von Geschäftsprozessen und deren Abhängigkeiten
- Service Dependency Mapping: Visualisierung von Serviceabhängigkeiten
Service-Monitoring ermöglicht es Unternehmen, die Auswirkungen von technischen Problemen auf Geschäftsprozesse zu verstehen und Prioritäten entsprechend zu setzen. Es hilft dabei, die Lücke zwischen IT und Business zu schließen und sicherzustellen, dass IT-Ressourcen auf die wichtigsten Geschäftsprozesse ausgerichtet sind.
Sicherheits-Monitoring
Das Sicherheits-Monitoring ist ein kritischer Bestandteil eines umfassenden Monitoring-Systems und umfasst:
- Security Information and Event Management (SIEM): Sammlung und Analyse von Sicherheitsereignissen
- Intrusion Detection/Prevention Systems (IDS/IPS): Erkennung und Verhinderung von Eindringversuchen
- Vulnerability Scanning: Regelmäßige Überprüfung auf Sicherheitslücken
- Compliance Monitoring: Überwachung der Einhaltung von Sicherheitsrichtlinien und Vorschriften
Sicherheits-Monitoring-Tools wie Splunk, IBM QRadar oder AlienVault helfen Unternehmen, Sicherheitsbedrohungen frühzeitig zu erkennen und darauf zu reagieren. Sie spielen eine entscheidende Rolle bei der Erkennung und Analyse von Bedrohungen und sind ein wesentlicher Bestandteil einer umfassenden Cybersicherheitsstrategie.
End-User-Experience-Monitoring
Das End-User-Experience-Monitoring konzentriert sich auf die Überwachung der Benutzererfahrung und umfasst:
- Real User Monitoring (RUM): Überwachung der tatsächlichen Benutzererfahrung
- Synthetic Monitoring: Simulation von Benutzerinteraktionen
- Digital Experience Monitoring (DEM): Umfassende Überwachung der digitalen Benutzererfahrung
End-User-Experience-Monitoring-Tools wie Dynatrace, AppDynamics oder ThousandEyes ermöglichen es Unternehmen, die Benutzererfahrung kontinuierlich zu überwachen und zu verbessern. Sie helfen dabei, Probleme aus Benutzerperspektive zu identifizieren und zu beheben, was zu einer höheren Kundenzufriedenheit führt.
Die Integration dieser verschiedenen Monitoring-Komponenten zu einem umfassenden System ermöglicht eine ganzheitliche Sicht auf die IT-Landschaft und bildet die Grundlage für ein effektives Event Management. Durch die Kombination von Infrastruktur-, Anwendungs-, Service-, Sicherheits- und End-User-Experience-Monitoring können Unternehmen eine 360-Grad-Sicht auf ihre IT-Umgebung erhalten und proaktiv auf potenzielle Probleme reagieren.
Der Event Management Prozess im Detail
Der Event Management Prozess ist ein strukturierter Ansatz zur Erkennung, Analyse und Behandlung von Ereignissen in der IT-Infrastruktur. Ein gut implementierter Prozess ermöglicht es Unternehmen, proaktiv auf potenzielle Probleme zu reagieren und die Auswirkungen von Störungen zu minimieren. Im Folgenden werden die einzelnen Schritte des Event Management Prozesses detailliert erläutert:
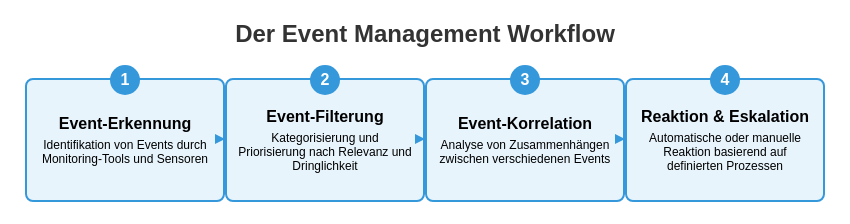
1. Event-Erkennung und -Aufzeichnung
Der erste Schritt im Event Management Prozess ist die Erkennung und Aufzeichnung von Ereignissen. Dies umfasst:
- Datenerfassung: Sammlung von Ereignisdaten aus verschiedenen Quellen wie Servern, Netzwerkgeräten, Anwendungen und Sicherheitssystemen
- Normalisierung: Umwandlung der Ereignisdaten in ein einheitliches Format
- Zeitstempelung: Versehen der Ereignisse mit genauen Zeitstempeln für spätere Analyse
Moderne Event Management Systeme können Tausende von Ereignissen pro Sekunde verarbeiten und diese in Echtzeit aufzeichnen. Die Herausforderung besteht darin, aus dieser Flut von Ereignissen die relevanten zu identifizieren.
2. Event-Filterung und -Kategorisierung
Nach der Erkennung und Aufzeichnung werden die Ereignisse gefiltert und kategorisiert, um ihre Relevanz und Bedeutung zu bestimmen. Dieser Schritt umfasst:
- Filterung: Ausfiltern von irrelevanten oder redundanten Ereignissen
- Kategorisierung: Einteilung der Ereignisse in Kategorien wie informativ, Warnung oder Ausnahme
- Prioritisierung: Zuweisung von Prioritäten basierend auf der Geschäftsrelevanz und potenziellen Auswirkungen
Durch effektive Filterung und Kategorisierung kann die Anzahl der zu bearbeitenden Ereignisse erheblich reduziert werden, was zu einer effizienteren Ressourcennutzung führt. Laut einer Studie von Gartner können bis zu 99% der generierten Events als informativ eingestuft werden und erfordern keine unmittelbare Aktion.
3. Event-Korrelation und -Priorisierung
Die Event-Korrelation ist ein kritischer Schritt im Event Management Prozess und umfasst:
- Korrelation: Identifizierung von Beziehungen zwischen verschiedenen Ereignissen
- Root Cause Analysis: Ermittlung der Grundursache für zusammenhängende Ereignisse
- Deduplizierung: Eliminierung von Duplikaten und redundanten Meldungen
- Priorisierung: Festlegung der Bearbeitungsreihenfolge basierend auf Geschäftsauswirkungen
Moderne Event Management Tools nutzen künstliche Intelligenz und Machine Learning, um Muster in Ereignisdaten zu erkennen und Korrelationen automatisch zu identifizieren. Dies reduziert das Problem der “Alert Fatigue” und ermöglicht es IT-Teams, sich auf die wichtigsten Probleme zu konzentrieren.
4. Automatisierte Reaktionen und Eskalation
Nach der Korrelation und Priorisierung werden automatisierte Reaktionen ausgelöst oder manuelle Eingriffe initiiert. Dieser Schritt umfasst:
- Automatisierte Reaktionen: Vordefinierte Aktionen zur Behebung bekannter Probleme
- Eskalation: Weiterleitung an zuständige Teams oder Personen
- Incident Creation: Erstellung von Incidents für Ereignisse, die manuelle Eingriffe erfordern
- Benachrichtigung: Information relevanter Stakeholder über kritische Ereignisse
Durch Automatisierung können bis zu 70% der routinemäßigen Probleme ohne menschliches Eingreifen gelöst werden, was zu einer schnelleren Problemlösung und reduzierten Betriebskosten führt. Ein effektives IT-Infrastrukturmanagement setzt zunehmend auf solche automatisierten Lösungen.
5. Überprüfung und Schließung
Der letzte Schritt im Event Management Prozess ist die Überprüfung und Schließung von Ereignissen. Dies umfasst:
- Verifizierung: Überprüfung, ob das Problem tatsächlich behoben wurde
- Dokumentation: Aufzeichnung der durchgeführten Aktionen und Ergebnisse
- Schließung: Formeller Abschluss des Ereignisses
- Analyse: Auswertung für kontinuierliche Verbesserung
Die Dokumentation und Analyse abgeschlossener Ereignisse ist entscheidend für die kontinuierliche Verbesserung des Event Management Prozesses. Durch die Identifizierung von Mustern und Trends können wiederkehrende Probleme erkannt und nachhaltig behoben werden.
Ein gut implementierter Event Management Prozess bildet die Grundlage für ein proaktives IT Service Management und ermöglicht es Unternehmen, potenzielle Probleme frühzeitig zu erkennen und zu beheben, bevor sie zu kritischen Störungen werden. Die Integration mit anderen ITIL-Prozessen wie Incident Management, Problem Management und Change Management ist dabei von entscheidender Bedeutung für ein ganzheitliches IT Service Management.
Tools und Technologien für effektives Monitoring
Die Auswahl der richtigen Tools und Technologien ist entscheidend für ein effektives IT Monitoring und Event Management. Der Markt bietet eine Vielzahl von Lösungen, die sich in Funktionsumfang, Komplexität und Preis unterscheiden. Im Folgenden werden die wichtigsten Kategorien von Monitoring-Tools und populäre Lösungen vorgestellt:
Übersicht über Monitoring-Tool-Kategorien
Monitoring-Tools lassen sich in verschiedene Kategorien einteilen, die jeweils spezifische Aspekte der IT-Umgebung überwachen:
- Infrastructure Monitoring Tools (IMT): Überwachung von Servern, Netzwerken und Speichersystemen
- Application Performance Monitoring (APM): Überwachung der Anwendungsleistung und -verfügbarkeit
- Network Performance Monitoring (NPM): Überwachung von Netzwerkgeräten und -verkehr
- Security Information and Event Management (SIEM): Sammlung und Analyse von Sicherheitsereignissen
- Digital Experience Monitoring (DEM): Überwachung der Benutzererfahrung
- AIOps Platforms: KI-gestützte Plattformen für intelligentes Monitoring und Automatisierung
Viele Unternehmen setzen auf eine Kombination verschiedener Tools, um alle Aspekte ihrer IT-Umgebung abzudecken. Zunehmend gewinnen jedoch integrierte Plattformen an Bedeutung, die mehrere Monitoring-Funktionen in einer einheitlichen Lösung zusammenfassen.
Vergleich populärer Monitoring-Lösungen
Der Markt für Monitoring-Tools ist vielfältig und bietet Lösungen für unterschiedliche Anforderungen und Budgets. Die folgende Tabelle gibt einen Überblick über einige der populärsten Lösungen:
| Tool | Kategorie | Hauptfunktionen | Vorteile | Nachteile | Geeignet für |
|---|---|---|---|---|---|
| Nagios | IMT | Server-, Netzwerk- und Anwendungsmonitoring | Open Source, hohe Anpassbarkeit, große Community | Steile Lernkurve, komplexe Konfiguration | Kleine bis mittlere Unternehmen mit technischem Know-how |
| Zabbix | IMT | Umfassendes Monitoring, Alerting, Visualisierung | Open Source, skalierbar, einfachere Konfiguration als Nagios | Ressourcenintensiv bei großen Umgebungen | Mittlere Unternehmen mit diversen Monitoring-Anforderungen |
| SolarWinds | IMT/NPM | Netzwerk-, Server- und Anwendungsmonitoring | Benutzerfreundlich, umfassende Dashboards | Relativ hohe Kosten, proprietäre Lösung | Mittlere bis große Unternehmen mit komplexen Netzwerken |
| Dynatrace | APM/DEM | Anwendungsperformance, User Experience, AI-gestützte Analyse | KI-basierte Problemerkennung, End-to-End-Monitoring | Hohe Kosten, komplex in großen Umgebungen | Große Unternehmen mit komplexen Anwendungslandschaften |
| New Relic | APM | Anwendungsperformance, Infrastruktur, Benutzermonitoring | Einfache Einrichtung, umfassende Einblicke | Kann bei großen Datenmengen teuer werden | Unternehmen mit Fokus auf Webanwendungen und Microservices |
| Splunk | SIEM | Log-Management, Sicherheitsanalyse, Monitoring | Leistungsstarke Suchfunktionen, hohe Flexibilität | Hohe Kosten, steile Lernkurve | Große Unternehmen mit umfangreichen Sicherheitsanforderungen |
| Prometheus | IMT | Metriken-basiertes Monitoring, Alerting | Open Source, ideal für Container-Umgebungen | Begrenzte Langzeitspeicherung, fokussiert auf Metriken | Unternehmen mit Kubernetes/Container-Umgebungen |
| Grafana | Visualisierung | Dashboards, Visualisierung, Alerting | Open Source, flexible Datenquellen-Integration | Kein eigenständiges Monitoring-Tool | Ergänzung zu anderen Monitoring-Tools |
Auswahlkriterien für die richtige Monitoring-Lösung
Die Auswahl der richtigen Monitoring-Lösung hängt von verschiedenen Faktoren ab und sollte sorgfältig geplant werden. Folgende Kriterien sollten bei der Auswahl berücksichtigt werden:
- Umfang und Komplexität der IT-Umgebung: Die Größe und Komplexität der zu überwachenden Umgebung bestimmt die Anforderungen an Skalierbarkeit und Funktionsumfang.
- Spezifische Monitoring-Anforderungen: Je nach Branche und Geschäftsmodell können spezifische Monitoring-Anforderungen bestehen, z.B. in Bezug auf Compliance oder Sicherheit.
- Integration mit bestehenden Systemen: Die Fähigkeit zur Integration mit bestehenden IT-Management-Systemen und Tools ist entscheidend für einen reibungslosen Betrieb.
- Skalierbarkeit und Performance: Die Lösung sollte mit dem Unternehmen mitwachsen können und auch bei steigender Datenmenge performant bleiben.
- Benutzerfreundlichkeit und Lernkurve: Die Benutzerfreundlichkeit und die erforderliche Einarbeitungszeit beeinflussen die Akzeptanz und Effektivität der Lösung.
- Kosten und ROI: Die Gesamtkosten (TCO) und der erwartete Return on Investment sollten in einem angemessenen Verhältnis stehen.
- Support und Community: Die Verfügbarkeit von professionellem Support und einer aktiven Community kann bei Problemen und Fragen hilfreich sein.
Eine gründliche Bedarfsanalyse und ein strukturierter Auswahlprozess sind entscheidend für die Identifizierung der am besten geeigneten Monitoring-Lösung. Viele Anbieter bieten Testversionen oder Proof-of-Concept-Installationen an, die genutzt werden sollten, um die Eignung der Lösung in der spezifischen Umgebung zu evaluieren.
Integration mit bestehenden IT-Systemen
Die Integration von Monitoring-Tools mit bestehenden IT-Systemen ist ein kritischer Erfolgsfaktor für ein effektives Monitoring und Event Management. Folgende Aspekte sollten bei der Integration berücksichtigt werden:
- ITSM-Integration: Die Integration mit IT Service Management Tools wie ServiceNow, Jira oder BMC Remedy ermöglicht die automatische Erstellung von Incidents und die Nachverfolgung von Problemen.
- CMDB-Integration: Die Integration mit der Configuration Management Database (CMDB) ermöglicht die Korrelation von Events mit den betroffenen Konfigurationselementen.
- Automatisierungs-Integration: Die Integration mit Automatisierungstools wie Ansible, Puppet oder Chef ermöglicht automatisierte Reaktionen auf bestimmte Events.
- API-Verfügbarkeit: Offene APIs erleichtern die Integration mit anderen Systemen und die Entwicklung von benutzerdefinierten Integrationen.
Eine erfolgreiche Integration erfordert eine sorgfältige Planung und oft auch die Anpassung von Prozessen und Workflows. Die Zusammenarbeit zwischen verschiedenen IT-Teams (Monitoring, Service Desk, Infrastruktur, Anwendungen) ist dabei von entscheidender Bedeutung.
Die Auswahl der richtigen Tools und Technologien ist ein wichtiger Schritt auf dem Weg zu einem effektiven IT Monitoring und Event Management. Eine sorgfältige Evaluation basierend auf den spezifischen Anforderungen und Gegebenheiten des Unternehmens ist entscheidend für den Erfolg. Die Integration mit bestehenden Systemen und die Anpassung von Prozessen und Workflows sind dabei ebenso wichtig wie die technischen Funktionen der ausgewählten Lösung.
Best Practices für die Implementierung
Die erfolgreiche Implementierung eines IT Monitoring und Event Management Systems erfordert mehr als nur die Auswahl der richtigen Tools. Eine durchdachte Strategie und die Beachtung bewährter Best Practices sind entscheidend für den langfristigen Erfolg. Im Folgenden werden die wichtigsten Best Practices für die Implementierung vorgestellt:
Definition von Monitoring-Zielen und KPIs
Bevor mit der Implementierung begonnen wird, sollten klare Ziele und Kennzahlen definiert werden, anhand derer der Erfolg des Monitoring-Systems gemessen werden kann. Typische KPIs für IT Monitoring und Event Management sind:
- Mean Time to Detect (MTTD): Die durchschnittliche Zeit bis zur Erkennung eines Problems
- Mean Time to Respond (MTTR): Die durchschnittliche Zeit bis zur Reaktion auf ein Problem
- Mean Time to Recovery (MTTR): Die durchschnittliche Zeit bis zur Wiederherstellung des Normalbetriebs
- Systemverfügbarkeit: Die prozentuale Verfügbarkeit kritischer Systeme
- Anzahl der Incidents: Die Anzahl der durch Monitoring erkannten und verhinderten Incidents
- Alert-to-Incident-Ratio: Das Verhältnis von Alerts zu tatsächlichen Incidents
Die Definition klarer Ziele und KPIs hilft nicht nur bei der Messung des Erfolgs, sondern auch bei der Priorisierung von Implementierungsaktivitäten und der Rechtfertigung von Investitionen gegenüber dem Management.
Festlegung von Schwellenwerten und Alarmen
Die Festlegung angemessener Schwellenwerte ist entscheidend für ein effektives Monitoring. Zu niedrige Schwellenwerte führen zu einer Flut von Alarmen, während zu hohe Schwellenwerte dazu führen können, dass wichtige Probleme übersehen werden. Folgende Prinzipien sollten bei der Festlegung von Schwellenwerten beachtet werden:
- Baseline-Erstellung: Vor der Festlegung von Schwellenwerten sollte eine Baseline des normalen Systemverhaltens erstellt werden.
- Differenzierte Schwellenwerte: Unterschiedliche Systeme und Anwendungen erfordern unterschiedliche Schwellenwerte.
- Dynamische Schwellenwerte: Moderne Monitoring-Tools unterstützen dynamische Schwellenwerte, die sich an das typische Verhalten anpassen.
- Mehrstufige Alarme: Die Implementierung von Warnungen und kritischen Alarmen ermöglicht eine differenzierte Reaktion.
- Regelmäßige Überprüfung: Schwellenwerte sollten regelmäßig überprüft und angepasst werden, um sich ändernden Bedingungen Rechnung zu tragen.
Eine sorgfältige Festlegung und regelmäßige Überprüfung von Schwellenwerten ist entscheidend, um die Balance zwischen zu vielen und zu wenigen Alarmen zu finden.
Vermeidung von Alert Fatigue
Alert Fatigue tritt auf, wenn IT-Teams mit zu vielen Alarmen konfrontiert werden, was dazu führen kann, dass wichtige Alarme übersehen oder ignoriert werden. Folgende Strategien helfen, Alert Fatigue zu vermeiden:
- Alarm-Konsolidierung: Zusammenfassung zusammenhängender Alarme zu einem einzigen Alarm
- Alarm-Deduplizierung: Eliminierung von Duplikaten und redundanten Alarmen
- Alarm-Priorisierung: Klare Priorisierung von Alarmen basierend auf Geschäftsauswirkungen
- Alarm-Unterdrückung: Temporäre Unterdrückung von Alarmen während geplanter Wartungsarbeiten
- Intelligente Alarmierung: Nutzung von KI und Machine Learning zur Identifizierung relevanter Alarme
Eine Studie von Gartner zeigt, dass Unternehmen, die Strategien zur Vermeidung von Alert Fatigue implementieren, die Anzahl der zu bearbeitenden Alarme um bis zu 90% reduzieren können, was zu einer höheren Effizienz und schnelleren Problemlösung führt.
Automatisierung von Routineaufgaben
Die Automatisierung von Routineaufgaben ist ein Schlüsselelement eines effektiven Monitoring und Event Management Systems. Folgende Bereiche eignen sich besonders für Automatisierung:
- Automatische Problemlösung: Vordefinierte Skripte zur automatischen Behebung bekannter Probleme
- Automatische Eskalation: Regelbasierte Eskalation von Problemen an die zuständigen Teams
- Automatische Dokumentation: Automatische Erfassung von Ereignissen und durchgeführten Aktionen
- Automatische Berichterstattung: Generierung von regelmäßigen Berichten über Systemzustand und Performance
Durch Automatisierung können IT-Teams von Routineaufgaben entlastet werden und sich auf komplexere Probleme konzentrieren, was zu einer höheren Effizienz und schnelleren Problemlösung führt. Laut einer Studie von McKinsey können bis zu 30% der IT-Betriebsaufgaben durch Automatisierung abgedeckt werden.
Kontinuierliche Verbesserung des Monitoring-Prozesses
Ein effektives Monitoring und Event Management System erfordert kontinuierliche Verbesserung und Anpassung an sich ändernde Anforderungen. Folgende Praktiken unterstützen die kontinuierliche Verbesserung:
- Regelmäßige Überprüfung: Regelmäßige Überprüfung der Monitoring-Strategie und -Implementierung
- Post-Incident-Reviews: Analyse von Incidents zur Identifizierung von Verbesserungspotenzial
- Feedback-Schleifen: Etablierung von Feedback-Mechanismen für Benutzer und Stakeholder
- Benchmarking: Vergleich mit Branchenstandards und Best Practices
- Schulung und Wissensaustausch: Kontinuierliche Schulung des IT-Teams und Förderung des Wissensaustauschs
Die kontinuierliche Verbesserung des Monitoring-Prozesses ist entscheidend, um mit der sich ständig ändernden IT-Landschaft Schritt zu halten und den maximalen Nutzen aus dem Monitoring-System zu ziehen.
Integration in das Change Management
Die Integration des Monitoring und Event Management Systems in das Change Management ist entscheidend, um Fehlalarme während geplanter Änderungen zu vermeiden und sicherzustellen, dass neue Systeme und Anwendungen angemessen überwacht werden. Folgende Praktiken unterstützen die Integration:
- Change-Benachrichtigungen: Automatische Benachrichtigung des Monitoring-Teams über geplante Änderungen
- Temporäre Alarm-Unterdrückung: Unterdrückung von Alarmen während geplanter Änderungen
- Monitoring-Anpassung: Anpassung des Monitorings an neue oder geänderte Systeme
- Post-Change-Validierung: Überprüfung der Monitoring-Konfiguration nach Änderungen
Eine enge Integration zwischen Monitoring und Change Management reduziert Fehlalarme und stellt sicher, dass alle Systeme angemessen überwacht werden. Dies ist besonders wichtig in dynamischen Umgebungen mit häufigen Änderungen.
Die Beachtung dieser Best Practices ist entscheidend für die erfolgreiche Implementierung eines IT Monitoring und Event Management Systems. Eine durchdachte Strategie, klare Ziele und KPIs, angemessene Schwellenwerte, Strategien zur Vermeidung von Alert Fatigue, Automatisierung von Routineaufgaben, kontinuierliche Verbesserung und Integration in das Change Management bilden die Grundlage für ein effektives und effizientes Monitoring-System, das einen echten Mehrwert für das Unternehmen bietet.
Fallstudien und Erfolgsbeispiele
Die praktische Anwendung von IT Monitoring und Event Management zeigt sich besonders deutlich in dokumentierten Erfolgsbeispielen. Laut einer Gartner-Studie konnten Unternehmen, die AIOps-Plattformen implementiert haben, ihre Problemlösungszeiten um durchschnittlich 50% reduzieren und die Anzahl kritischer Incidents um mehr als 30% senken.
Erfolgsbeispiel: Finanzdienstleister optimiert Monitoring
Ein europäischer Finanzdienstleister mit über 2.000 Mitarbeitern konnte durch die Implementierung einer zentralen Monitoring-Plattform beeindruckende Ergebnisse erzielen. Durch die Konsolidierung von acht verschiedenen Monitoring-Tools auf eine einheitliche Lösung und die Einführung automatisierter Event-Korrelation wurden folgende Verbesserungen dokumentiert:
- Reduzierung der Anzahl der Alarme um 65% durch intelligente Korrelation
- Verkürzung der durchschnittlichen Problemlösungszeit um 58%
- Jährliche Kosteneinsparungen von über 400.000 Euro durch reduzierte Lizenzkosten und vermiedene Ausfälle
- Verbesserte Zusammenarbeit zwischen IT-Teams durch eine einheitliche Sichtweise
Laut dem BSI IT-Grundschutz-Kompendium ist ein strukturiertes Monitoring besonders für Finanzdienstleister mit ihren hohen Compliance-Anforderungen unverzichtbar.
Übertragbare Erkenntnisse für Ihr Unternehmen
Aus dokumentierten Fallstudien lassen sich folgende übertragbare Erkenntnisse ableiten:
- Ganzheitlicher Ansatz: Ein ganzheitlicher Ansatz, der Infrastruktur, Anwendungen und Sicherheit umfasst, liefert die besten Ergebnisse.
- Klare Ziele und KPIs: Die Definition klarer Ziele und messbarer KPIs ist entscheidend für den Erfolg.
- Schrittweise Implementierung: Eine schrittweise Implementierung reduziert Risiken und ermöglicht frühzeitige Erfolge.
- Automatisierung: Die Automatisierung von Routineaufgaben verbessert die Effizienz und reduziert menschliche Fehler.
Eine Splunk-Studie zum “State of Monitoring” bestätigt, dass Unternehmen mit ausgereiften Monitoring-Praktiken im Durchschnitt 70% weniger Ausfallzeiten verzeichnen als solche mit reaktiven Ansätzen.
Zukunftstrends im IT Monitoring & Event Management
Die Welt des IT Monitoring entwickelt sich kontinuierlich weiter, angetrieben durch technologische Innovationen und neue IT-Paradigmen. Drei zentrale Trends werden die Zukunft in diesem Bereich maßgeblich prägen:
- KI und Machine Learning: Laut einer Gartner-Studie werden bis 2025 mehr als 50% der Unternehmen KI-gestützte Monitoring-Lösungen einsetzen. Diese Technologien ermöglichen intelligente Anomalieerkennung, automatische Event-Korrelation und präzise Root-Cause-Analysen.
- Predictive Analytics: Der Wandel von reaktivem zu proaktivem Monitoring ermöglicht die Vorhersage potenzieller Probleme, bevor sie auftreten. IDC-Forschungen zeigen, dass Unternehmen mit Predictive Analytics ihre ungeplanten Ausfallzeiten um bis zu 85% reduzieren können.
- Self-Healing-Systeme: Automatisierte Reaktionen und selbstreparierende Infrastrukturen reduzieren den manuellen Aufwand erheblich. Forrester prognostiziert, dass bis 2026 etwa 60% der Unternehmen Self-Healing-Technologien implementieren werden.
Diese Entwicklungen versprechen ein effizienteres, proaktiveres und autonomeres IT Monitoring, das IT-Teams entlastet und die Systemverfügbarkeit signifikant verbessert.
Die Zukunft des IT Monitoring und Event Management wird geprägt sein von intelligenten, proaktiven und automatisierten Lösungen, die eng in den gesamten IT-Lebenszyklus integriert sind. Unternehmen, die diese Trends frühzeitig erkennen und nutzen, werden in der Lage sein, ihre IT-Betriebseffizienz zu steigern, Ausfallzeiten zu reduzieren und einen echten Wettbewerbsvorteil zu erzielen.
Die Implementierung dieser zukunftsweisenden Technologien erfordert jedoch nicht nur technisches Know-how, sondern auch eine Anpassung von Prozessen, Organisationsstrukturen und Unternehmenskultur. Unternehmen sollten daher einen ganzheitlichen Ansatz verfolgen und die Einführung neuer Monitoring-Technologien als Teil einer breiteren digitalen Transformationsstrategie betrachten.
Fazit und Handlungsempfehlungen
IT Monitoring und Event Management sind kritische Komponenten eines effektiven IT Service Managements und bilden die Grundlage für eine stabile, zuverlässige IT-Infrastruktur. In einer zunehmend digitalisierten Geschäftswelt, in der die Verfügbarkeit von IT-Systemen direkt mit dem Geschäftserfolg verknüpft ist, gewinnen diese Disziplinen weiter an Bedeutung.
Die in diesem Artikel vorgestellten Konzepte, Best Practices und Zukunftstrends zeigen, dass ein modernes IT Monitoring und Event Management weit über die reine Überwachung von Systemen hinausgeht. Es handelt sich vielmehr um einen ganzheitlichen Ansatz, der Technologie, Prozesse und Menschen umfasst und darauf abzielt, potenzielle Probleme proaktiv zu erkennen und zu beheben, bevor sie zu kritischen Störungen werden.
Die wichtigsten Erkenntnisse lassen sich wie folgt zusammenfassen:
- Proaktiver Ansatz: Ein proaktives Monitoring und Event Management ermöglicht die frühzeitige Erkennung und Behebung von Problemen, was zu einer höheren Systemverfügbarkeit und reduzierten Ausfallzeiten führt.
- Ganzheitliche Sicht: Ein umfassendes Monitoring-System sollte Infrastruktur, Anwendungen, Services, Sicherheit und Benutzererfahrung abdecken, um eine 360-Grad-Sicht auf die IT-Umgebung zu bieten.
- Intelligente Analyse: Moderne Monitoring-Lösungen nutzen KI und Machine Learning, um aus der Flut von Ereignissen die relevanten zu identifizieren und komplexe Zusammenhänge zu erkennen.
- Automatisierung: Die Automatisierung von Routineaufgaben und die Entwicklung von Self-Healing-Systemen verbessern die Effizienz und reduzieren menschliche Fehler.
- Integration: Die Integration des Monitorings in den gesamten IT-Lebenszyklus, von der Entwicklung bis zum Betrieb, fördert eine Kultur der gemeinsamen Verantwortung für die Servicequalität.
- Kontinuierliche Verbesserung: Ein kontinuierlicher Verbesserungsprozess stellt sicher, dass das Monitoring-System mit den sich ändernden Anforderungen Schritt hält.
Basierend auf diesen Erkenntnissen lassen sich folgende Handlungsempfehlungen für Unternehmen ableiten:
Konkrete Schritte zur Verbesserung des eigenen Monitoring-Systems
- Bestandsaufnahme und Analyse: Führen Sie eine detaillierte Bestandsaufnahme Ihrer IT-Infrastruktur und bestehenden Monitoring-Lösungen durch. Identifizieren Sie Lücken und Verbesserungspotenzial.
- Strategie und Ziele definieren: Entwickeln Sie eine klare Monitoring-Strategie mit messbaren Zielen und KPIs, die an den Geschäftszielen ausgerichtet sind.
- Toolauswahl und -integration: Wählen Sie Monitoring-Tools, die Ihren spezifischen Anforderungen entsprechen und sich in Ihre bestehende IT-Landschaft integrieren lassen.
- Implementierung und Konfiguration: Implementieren Sie die ausgewählten Tools schrittweise und konfigurieren Sie sie entsprechend Ihren Anforderungen. Beginnen Sie mit kritischen Systemen und erweitern Sie den Umfang schrittweise.
- Prozesse und Workflows definieren: Definieren Sie klare Prozesse und Workflows für das Event Management, einschließlich Eskalationspfaden und Verantwortlichkeiten.
- Automatisierung implementieren: Identifizieren Sie Routineaufgaben, die automatisiert werden können, und implementieren Sie entsprechende Automatisierungslösungen.
- Schulung und Wissensaufbau: Schulen Sie Ihr IT-Team in der Nutzung der Monitoring-Tools und fördern Sie den Wissensaustausch.
- Kontinuierliche Verbesserung etablieren: Etablieren Sie einen kontinuierlichen Verbesserungsprozess mit regelmäßigen Reviews und Anpassungen.
Die Implementierung eines effektiven IT Monitoring und Event Management Systems ist keine einmalige Aufgabe, sondern ein kontinuierlicher Prozess, der Anpassung und Verbesserung erfordert. Unternehmen, die diesen Prozess erfolgreich gestalten, werden in der Lage sein, ihre IT-Betriebseffizienz zu steigern, Ausfallzeiten zu reduzieren und einen echten Wettbewerbsvorteil zu erzielen.
In einer Zeit, in der die digitale Transformation nahezu alle Branchen erfasst, wird die Fähigkeit, IT-Systeme zuverlässig zu betreiben und potenzielle Probleme proaktiv zu erkennen und zu beheben, zu einem entscheidenden Erfolgsfaktor. Ein modernes, intelligentes IT Monitoring und Event Management System bildet dafür die Grundlage.
Häufig gestellte Fragen
Was ist der Unterschied zwischen IT Monitoring und Event Management?
IT Monitoring ist die kontinuierliche Überwachung von IT-Systemen, während Event Management die Erkennung und Behandlung von Ereignissen umfasst. Monitoring liefert die Rohdaten, Event Management wandelt diese in verwertbare Erkenntnisse um und leitet entsprechende Maßnahmen ein. Beide Disziplinen ergänzen sich: Monitoring erfasst, Event Management interpretiert und reagiert.
Welche Monitoring-Tools eignen sich für kleine und mittlere Unternehmen?
Für KMUs eignen sich Open-Source-Lösungen wie Zabbix, Nagios oder Icinga (kostenfrei, erfordern technisches Know-how) sowie Cloud-basierte Dienste wie Datadog, New Relic oder Dynatrace (einfachere Einrichtung, laufende Kosten). Die Wahl sollte auf Basis der spezifischen Anforderungen, des vorhandenen Know-hows und des Budgets getroffen werden.
Wie kann ich Alert Fatigue in meinem Unternehmen reduzieren?
Alert Fatigue lässt sich reduzieren durch: präzise Schwellenwerte basierend auf normalen Systemverhalten, mehrstufige Alarme (Warnungen vs. kritische Alarme), Alarm-Konsolidierung und -Korrelation, KI-gestützte Alarmierung zur Minimierung falsch-positiver Meldungen sowie regelmäßige Überprüfung und Anpassung der Alarmkonfigurationen.
Welche KPIs sollte ich für mein IT Monitoring & Event Management verfolgen?
Wichtige KPIs sind: Mean Time to Detect (MTTD), Mean Time to Respond (MTTR), Mean Time to Recovery (MTTR), Systemverfügbarkeit, Anzahl der Incidents, Alert-to-Incident-Ratio und Automatisierungsgrad. Diese Kennzahlen sollten regelmäßig überprüft werden, um kontinuierliche Verbesserungen zu ermöglichen.
Wie integriere ich Monitoring in meine bestehende IT-Infrastruktur?
Für eine erfolgreiche Integration: Führen Sie eine Bestandsaufnahme durch, entwickeln Sie eine klare Monitoring-Strategie, wählen Sie Tools mit guten Integrationsmöglichkeiten, implementieren Sie schrittweise (beginnend mit kritischen Systemen), integrieren Sie mit bestehenden IT-Management-Systemen und etablieren Sie einen kontinuierlichen Verbesserungsprozess.